But all is not lost! Your remember hearing about a technique from you college psychometrics class that did exactly the same thing. Item sampling was suggested by Lord and Novick in their classic 1968 text introducing item response theory (chapter 11). If the focus is the school (brand) and not individual students (customers), we can obtain everything we need by randomly selecting only some proportion of the items to be given to each examinee (respondent).
Suppose that a brand is concerned about how well it delivers on a sizable number of different product features and services. The company is determined to track them all, possibly in order to maintain quality control. Obviously, the brand needs enough respondent ratings for each item to yield stable estimates at the brand level, but the individual respondent is largely irrelevant, except as a means to an end. To accomplish their objective, no item can be deleted from the battery, but no respondent needs to rate them all.
One might object that we still require individual-level data if we wish to estimate the parameters of a regression model that will tells us, for example, the effect of customer satisfaction on important outcomes such as customer retention. But do we really need all 12 satisfaction ratings in the regression model? Does each rating provide irreplaceable information about the individual customer so that removing any one item leaves us without the data we need? Or, is there enough redundancy in the ratings that little is lost when a respondent rates only a random sample of the items?
Graded Response Model to the Rescue
Item response theory provides an answer. Specifically, the graded response model introduced in a prior post, Item Response Modeling of Customer Satisfaction, will give us an estimate of what information we lose when items are sampled. As you might recall from that post, we had a data set with over 4000 respondents who had completed a customer satisfaction scale after taking a flight with a major airline. Since most of our studies will not have data from so many respondents, we can randomly select a small number of observations and work with a more common sample size. If we wish to obtain the same sample every time, we will need to set the random seed. The original 4000+ data set was called data. The R function sample randomly selects without replacement 500 rows.
set.seed(12345)
sample <- data[sample(1:nrow(data), 500, replace=FALSE),]
Now, we can rerun the graded response model with 500 random observations. But, we remember that the satisfaction ratings were highly skewed so that we cannot be certain that all possible category levels will be observed for all 12 ratings given we now have only 500 respondents. For example, the ltm package would generate an error message if no one gave a rating of "one" to one of the 12 items. Following the example on R wiki (look under FAQ), we use lapply to encode the variables of the data frame as factors.
sample.new <- sample
sample.new[] <- lapply(sample, factor)
With the variables as factors, we need not worry about receiving an error, and we can run the graded response model using the ltm package as we did in the previous post.
library(ltm)
fit <- grm(sample.new)
pattern <- factor.scores(fit, resp.pattern=sample.new)
trait <- pattern$score.dat$z1
The factor.scores function does the work of calculating the latent trait score for satisfaction. It creates an object that we have called pattern in the above code. The term "pattern" was chosen because the object contains all the ratings upon which the latent score was based. That is, factor.scores outputs an object with the response pattern and the z-score for the latent trait. We have copied this z-score to a variable called trait.
The next step is to sample some portion of the items and rerun the graded response model with the items not sampled set equal to the missing value NA. In this way we are able to recreate the data matrix that would have resulted had we sampled items from the original questionnaire. There are many ways to accomplish such item sampling, but I find the following procedure to be intuitive and easy to explain.
set.seed(54321)
sample_items <- NULL
for (i in 1:500) {
sample_items <- rbind(simple_items, sample(1:12,12))
}
sample_test <- sample
sample_test[sample_items>6] <- NA
The above R code creates a new matrix called sample_items that is the same size as the data file in the data frame called sample (i.e., 500 x 12). Each row of sample_items contains the numbers one through 12 in random order. In order to randomly sample six of the 12 items, I have set the criterion for NA assignment as sample_items>6. Had I wanted to sample only three items, I would have set the criterion to sample_items>3.
Once again, we need to recode the variables to be factors in order to avoid any error messages from the ltm package when one or more items have one or more category levels with no observations. Then, we rerun the graded response model with half the data missing.
sample_test.new <- sample_test
sample_test.new[] <- lapply(sample_test, factor)
fit_test<-grm(sample_test.new)
fit_sample_test<-grm(sample_test,new)
pattern_sample_test<-factor.scores(fit_sample_test, resp.pattern=sample_test.new)
trait_sample_test<-pattern_sample_test$score.dat$z1
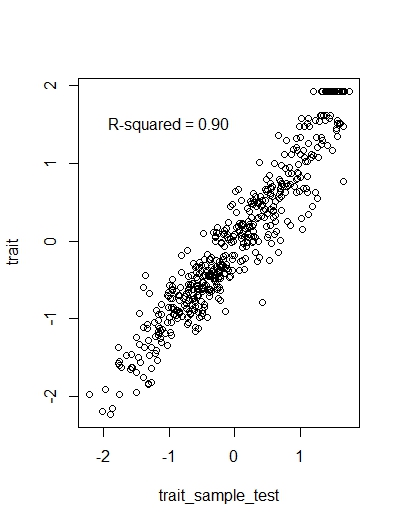
This is a good time to pause and reflect. We started with the belief that our 12 satisfaction ratings were all measuring the same underlying latent trait. They may be measuring some more specific factors, in addition to the general factor, as we saw from our bifactor model in the prior post. But clearly, all 12 items are tapping something in common, which we are calling latent customer satisfaction.
Does every respondent need to rate all 12 items in order for us to estimate each respondent's level of latent customer satisfaction? How well might we do if only half the items were randomly sampled? We now have two estimates of our latent trait, one from each respondent rating all 12 items and one with each respondent rating a one-half item sampling. A simple regression equation should tell us the relationship between the two estimates.
Caveats and Alternatives
The objectives for this post were somewhat limited. Primarily, I wanted to reintroduce "item sampling" to the marketing research and R communities. Graded response modeling in the ltm package seemed to be the most direct way of accomplishing this. First, I believed that this approach would create the least confusion. Second, it provided a good opportunity for us to become more familiar with the ltm package and its capabilities. However, we need to be careful.
As the amount of missing value increases, greater burdens are placed on any estimation procedure, including the grm and factor.scores functions in the ltm package. Although as we saw in this example, ltm had no difficulty handling item sampling using a sampling ratio of 0.5, but we will need to exercise care as the sampling ratio falls under one half. As you might expect, R is full of missing value estimation packages (see missing data under multivariate task view). Should we estimate missing values first and then run the graded response model? Or, perhaps we should collect a calibration sample with these respondents completing all the ratings? The graded response model estimates from the calibration sample would be used to calculate latent trait scores from the item sampling data for all future respondents.
These are all good questions, but first we must think outside the common practice of requiring everyone to complete every rating. It is necessary to have all the respondents rate all the items only when each item provides unique information. We may seldom find ourselves in such a situation. More often, items are added to the questionnaire for what might be called "political" reasons (e.g., as a signal to employees that the company values the feature or service rated or to appease an important constituency in the company). Item sampling provides a doable compromise allowing us to please everyone and reduce respondent burden at the same time.
Joel, very nice post. I was expecting, however, that you would establish a comparison with CAT where the choice of the next item is based on previous scores rather than random
ReplyDeleteGood point, Ricardo. I thought about it, but the post was getting a little long. I do provide a link to an R-based computerized adaptive testing program called Concerto from the Psychometrics Centre at Cambridge University in my latest post (Call for Context-Aware Measurement). It gets a little more complicated to explain how to pick the next item when the response scale has more than two levels. But you are right that it might help at the extremes when a respondent consistently gives the highest or the lowest ratings to ask "harder" or "easier" items. Thanks for taking the time to make a comment.
Delete